Qu’est-ce qu’une base de données ?
Une base de données est un moyen de stocker électroniquement des collections de données de manière organisée.
Imagine que tu as un grand coffre à trésors où tu veux ranger plein de choses.

Maintenant, tu as besoin d’un moyen ranger ces choses de façon bien organisé. C’est là qu’intervient le SGBD (Système de Gestion de Base de Données) acronyme de Data base Management System DBMS. C’est comme un guide qui te dit comment bien ranger tes choses de manière bien organisé et retrouver.
Il existe deux types principaux de bases de données : les bases de données relationnelles et les bases de données non relationnelles (également appelées bases de données NoSQL).
les bases de données relationnelles :
Bon, tu as un grand coffre à trésors où tu veux ranger plein de choses. Pour que tu puisses bien organiser tout ce que tu mets dedans, tu décides de diviser ton coffre en plusieurs petites boîtes. Chaque boîte est une table dans ta base de données.
Maintenant, dans chaque boîte (ou table), tu veux ranger des objets similaires. Par exemple, dans une boîte, tu peux ranger tous tes jouets, dans une autre boîte, tu peux mettre tous tes livres, et ainsi de suite. Chaque objet que tu mets dans une boîte est comme une rangée dans ta table.

Chaque boîte (table) est aussi divisée en sections, appelées colonnes. Chaque colonne a un nom qui te dit ce que tu devrais ranger dedans. Par exemple, dans la boîte à jouets, tu peux avoir une colonne appelée « Nom du jouet », une autre colonne appelée « Couleur », et ainsi de suite. Chaque colonne est comme une caractéristique spécifique que tu veux savoir sur chaque objet que tu ranges dans la boîte.
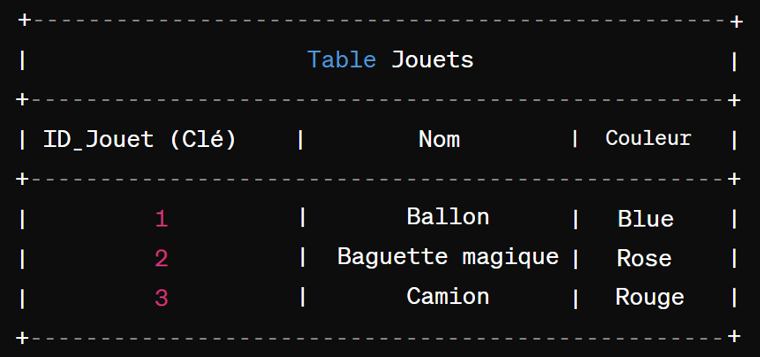
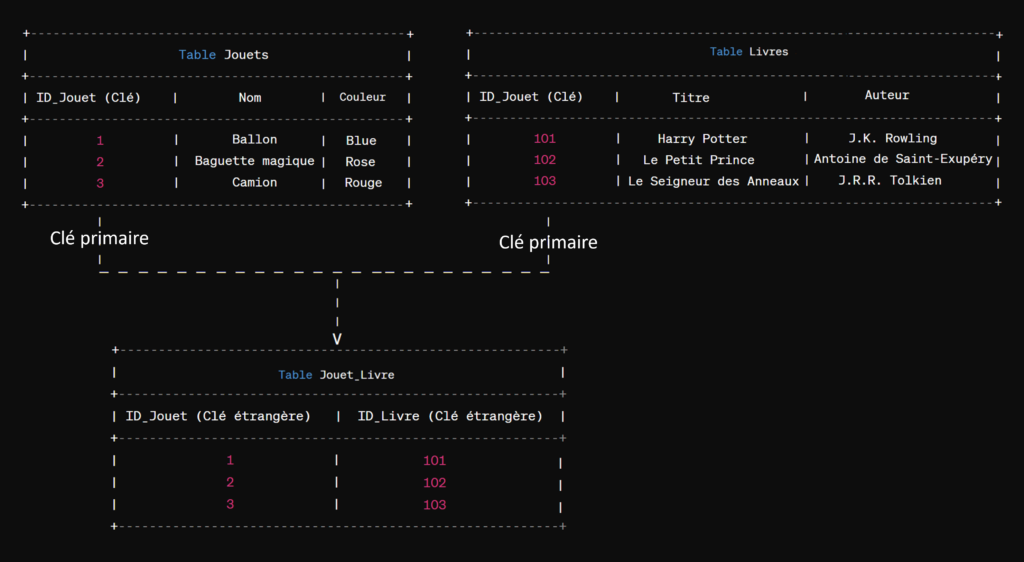
Maintenant, pour savoir exactement de quel objet il s’agit dans chaque boîte, tu peux utiliser un identifiant unique. C’est comme un numéro de série. Chaque objet que tu mets dans une boîte a son propre numéro de série, qui est unique. Cet identifiant unique est appelé clé primaire.

Et enfin, pour rendre les choses encore plus intéressantes, tu peux lier certaines boîtes entre elles en utilisant des clés. Par exemple, si tu as une boîte à jouets et une boîte à livres, et que certains jouets sont basés sur des personnages de livres. Comme baguette magique lié au livre de Harry Potter.
Prenons maintenant un autre exemple plus réel. Le cas du réseau social TWITTER. Tu as un utilisateur qui poste des tweets et qui a des followers ainsi que des personnes qu’il suit. Donc, nous aurons par exemple des tables pour les utilisateurs de Twitter, une autre pour les tweets, et une autre pour les relations entre utilisateurs.
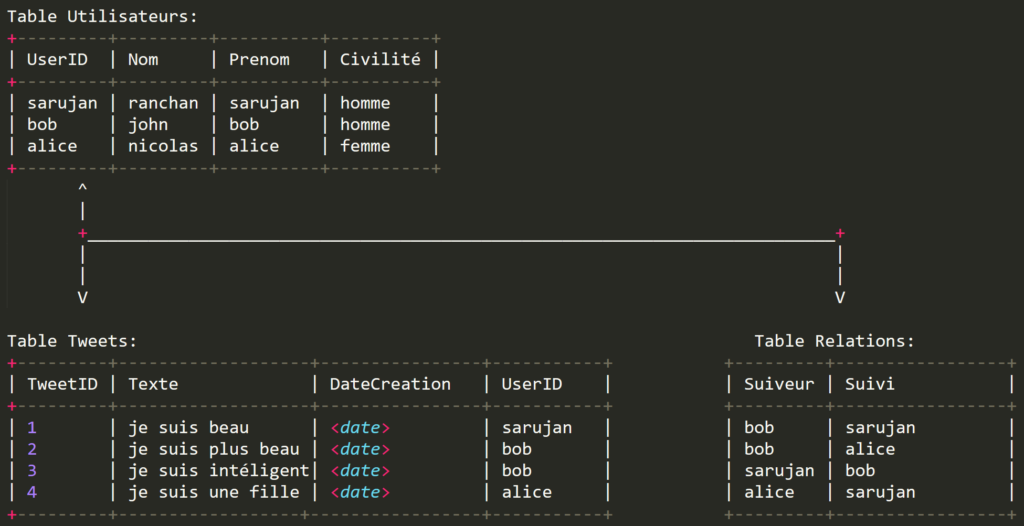
La table de relation est composée de deux colonnes, field, qui contiennent toutes les deux les clés primaires de la table Utilisateurs. On appelle cela des clés étrangères. La table est composée de clés étrangères qui sont à la base des clés primaires de la table utilisateurs
Les bases de données non relationnelles :
Une base de données non relationnelle, également appelée base de données NoSQL, diffère d’une base de données relationnelle traditionnelle en ce qu’elle ne suit pas le modèle de données tabulaire avec des tables, des colonnes et des lignes interconnectées par des clés étrangères.
Dans une base de données non relationnelle, les données sont stockées d’une manière plus flexible et souvent plus adaptée à des types de données complexes ou évolutifs, tels que des documents JSON, des paires clé-valeur, des graphiques ou des colonnes larges.
Voici quelques types courants de bases de données NoSQL
Base de données orientée document :
Stocke les données dans des documents, généralement au format JSON ou BSON. Chaque document peut avoir une structure différente.
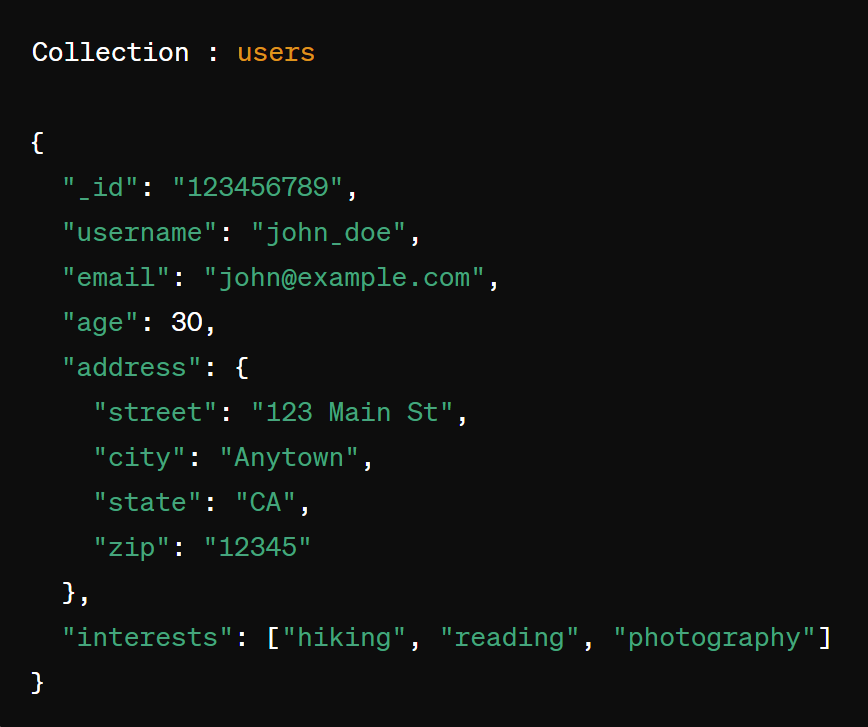
Dans cet exemple, nous avons une collection appelée « users » qui stocke des documents au format JSON. Chaque document représente un utilisateur avec des champs comme « username », « email », « age », « address » et « interests ». La clé « _id » est une clé unique générée automatiquement pour chaque document.
Ce modèle est très flexible, car chaque document peut avoir une structure différente. Par exemple, certains utilisateurs peuvent avoir des champs supplémentaires ou manquants sans affecter les autres documents dans la collection. Cela rend la base de données orientée document idéale pour les applications avec des données semi-structurées ou évolutives.
Base de données orientée colonnes :
Stocke les données dans des colonnes plutôt que des lignes, ce qui permet une récupération rapide des données spécifiques.

Dans cet exemple, nous avons une table appelée « sales » qui stocke des données sur les ventes. Chaque colonne représente un attribut des ventes, comme la « Date », le « Produit », la « Région » et le « Montant ». Chaque ligne de la table représente une vente individuelle.
Ce modèle est efficace pour les requêtes qui agrègent des données sur une ou plusieurs colonnes spécifiques. Par exemple, pour obtenir le montant total des ventes par région, nous pouvons utiliser une requête qui regroupe les données par colonne « Région » et calcule la somme du montant.
Il y a des similitudes entre les représentations des bases de données orientées colonnes et relationnelles. Dans les deux cas, nous utilisons des tables pour organiser les données en lignes et en colonnes. Cependant, la principale différence réside dans la manière dont les données sont stockées physiquement et dans la façon dont les requêtes sont optimisées.
Dans une base de données orientée colonnes, les données sont stockées de manière à regrouper les valeurs des mêmes colonnes ensemble, ce qui permet une meilleure compression et une récupération plus rapide des données lors de l’exécution de requêtes qui impliquent des colonnes spécifiques. Cela rend ce modèle particulièrement adapté aux cas d’utilisation où les requêtes agrègent ou analysent un grand nombre de colonnes, comme les analyses de données ou les rapports commerciaux.
En revanche, dans une base de données relationnelle traditionnelle, les données sont généralement stockées sous forme de lignes contiguës, ce qui facilite la récupération des enregistrements individuels. Ce modèle est souvent privilégié pour les opérations transactionnelles et les requêtes qui portent sur un petit nombre de colonnes à la fois.
Dans une base de données orientée colonnes, les colonnes jouent un rôle clé dans la structure et l’organisation des données. Chaque colonne représente un attribut spécifique des données et les valeurs de cette colonne sont stockées ensemble pour chaque enregistrement. Ainsi, chaque colonne agit comme un identifiant naturel pour les données qu’elle contient.
Contrairement aux bases de données relationnelles où les lignes sont identifiées par des clés primaires ou des identifiants uniques, dans une base de données orientée colonnes, les valeurs des colonnes elles-mêmes servent souvent de moyen d’identification. Cela signifie que chaque colonne peut potentiellement être utilisée pour rechercher, trier ou filtrer les données en fonction des besoins de l’application ou de la requête.
Base de données orientée clé-valeur :
Stocke les données sous forme de paires clé-valeur simples, où chaque clé est unique et est associée à une seule valeur.

Les bases de données orientées clé-valeur sont souvent utilisées pour stocker des données simples et non structurées, telles que des paramètres de configuration, des préférences utilisateur ou des sessions de connexion. Elles sont efficaces pour des opérations de lecture et d’écriture rapides sur de grandes quantités de données, mais elles peuvent ne pas être idéales pour des requêtes complexes ou des relations entre les données.
Chaque enregistrement est représenté par une paire clé-valeur, où la clé est unique et les valeurs associées peuvent être structurées de différentes manières. Dans l’exemple que j’ai donné, « employe1 », « employe2 », etc. sont les clés uniques identifiant chaque enregistrement (ou employé), et les détails de chaque employé (nom, âge, ville) sont les valeurs associées à ces clés.
Chaque enregistrement (employé) possède ses propres données, qui peuvent être structurées comme des paires clé-valeur imbriquées. Ainsi, « nom », « age » et « ville » sont les clés à l’intérieur de chaque enregistrement, et leurs valeurs sont les détails spécifiques de chaque employé.
Base de données orientée graphe :
Stocke les données sous forme de graphiques, où les entités sont représentées par des nœuds et les relations entre les entités sont représentées par des arêtes.
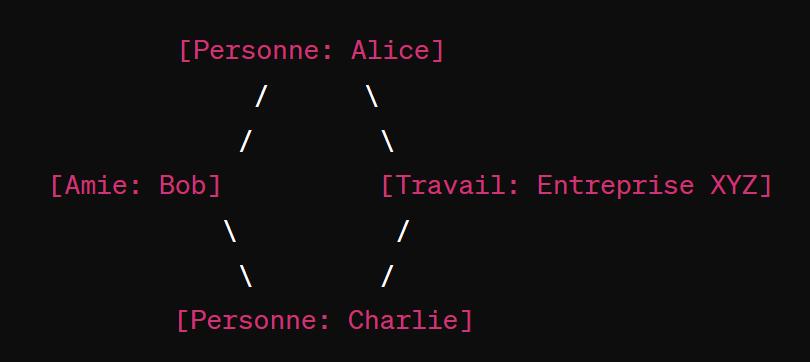
Dans cet exemple, « Personne: Alice » et « Personne: Charlie » sont des nœuds représentant des personnes, « Amie: Bob » et « Travail: Entreprise XYZ » sont des nœuds représentant des relations entre les personnes et d’autres entités.
Alice est reliée à Bob en tant qu’amie, et à l’entreprise XYZ en tant qu’employée. Charlie est également relié à l’entreprise XYZ. Les relations entre les nœuds représentent des liens significatifs dans les données, permettant de modéliser des structures complexes de manière flexible.
Dans un système informatique, une base de données orientée graphe est généralement stockée de manière structurée sur un support de stockage tel qu’un disque dur. Voici comment cela peut être réalisé :
- Nœuds : Chaque nœud est enregistré individuellement avec toutes ses propriétés et ses attributs. Par exemple, pour le nœud « Personne: Alice », toutes les informations sur Alice (comme son nom, son âge, etc.) sont stockées ensemble.
- Relations : Les relations entre les nœuds sont généralement stockées sous forme de listes d’adjacence ou de matrices d’adjacence. Ces structures permettent de représenter les connexions entre les nœuds de manière efficace. Par exemple, une liste d’adjacence pourrait indiquer que « Personne: Alice » est reliée à « Amie: Bob » et à « Travail: Entreprise XYZ ».
- Indexation : Pour faciliter les recherches et les parcours dans le graphe, des index peuvent être utilisés pour enregistrer les relations entre les nœuds. Ces index permettent d’accéder rapidement aux nœuds et aux relations pertinents lors de l’exécution de requêtes.
Dans le cas de l’exemple avec Alice et Charlie, un index pourrait être utilisé pour enregistrer les relations entre les nœuds de manière efficace. Voici comment cela pourrait fonctionner :
Supposons que nous ayons un graphe avec les nœuds suivants :
- Nœud 1 : Personne: Alice
- Nœud 2 : Personne: Bob
- Nœud 3 : Personne: Charlie
Et les relations suivantes :
- Relation 1 : « Amie » entre Alice et Bob
- Relation 2 : « Amie » entre Alice et Charlie
Pour indexer ces relations, nous pourrions avoir un index qui enregistre les relations entre les nœuds de la manière suivante :
- Index :
- Clé : Personne: Alice
- Valeur : Liste des relations associées à Alice (par exemple, « Amie » avec Bob et Charlie)
- Clé : Personne: Bob
- Valeur : Liste des relations associées à Bob (par exemple, « Amie » avec Alice)
- Clé : Personne: Charlie
- Valeur : Liste des relations associées à Charlie (par exemple, « Amie » avec Alice)
- Clé : Personne: Alice
Cet index nous permettrait d’accéder rapidement aux relations de chaque personne sans avoir à parcourir tout le graphe. Ainsi, lors de l’exécution de requêtes comme « Quels sont les amis d’Alice ? », nous pourrions consulter l’index pour obtenir rapidement la liste des amis d’Alice.
Parlant de l’index il est intéressant de faire le lien avec un cas réele d’utilisation des index:Dans le cas des siem comme Splunk,ELK les logs sont traité analysé puis indexé pour pouvoir faire des requette plus rapidement et efficacement.
voici deux exemples de logs et comment ils pourraient être extraits et stockés sous forme de champs (fields) dans Splunk :
Exemple de log Apache Access :
192.168.1.1 – – [16/Jan/2024:12:34:56 +0000] « GET /page.html HTTP/1.1 » 200 1234 « http://example.com » « Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.4567.89 Safari/537.36 »
Champs potentiels (fields) :
client_ip: 192.168.1.1timestamp: 16/Jan/2024:12:34:56 +0000method: GETurl: /page.htmlprotocol: HTTP/1.1status_code: 200response_size: 1234referrer: http://example.comuser_agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.4567.89 Safari/537.36
Exemple de log Syslog d’un routeur Cisco :
%SYS-5-CONFIG_I: Configured from console by admin on vty0 (192.168.1.1)
Champs potentiels (fields) :
severity: SYSfacility: CONFIGmessage: Configured from console by admin on vty0 (192.168.1.1)
Les champs(fields) dans Splunk sont des éléments individuels extraits des logs qui fournissent des informations spécifiques sur chaque événement. Par exemple, dans un log Apache Access, les champs pourraient être l’adresse IP du client, l’URL demandée, le code de réponse HTTP, etc. Chaque champ a un nom et une valeur associés.Et un index dans le siem Splunk est similaire à une base de données dans laquelle les données sont stockées. Chaque index contient des événements (logs) qui sont segmentés en plusieurs champs pour faciliter l’analyse et la recherche ultérieure.
Dans les exemples que j’ai donnés précédemment, voici comment ils pourraient être utilisés dans Splunk :
- Apache Access Log :
- Champs :
client_ip,timestamp,method,url,protocol,status_code,response_size,referrer,user_agent - Ces champs peuvent être extraits à l’aide d’expressions régulières ou de délimiteurs spécifiques dans Splunk et indexés dans un index dédié, par exemple
apache_access_index.
- Champs :
- Syslog Cisco Router Log :
- Champs :
severity,facility,message - De la même manière, ces champs peuvent être extraits et indexés dans un index spécifique, par exemple
cisco_syslog_index.
- Champs :
Une fois que les données sont indexées dans Splunk avec les champs appropriés, les utilisateurs peuvent utiliser ces champs pour effectuer des recherches, créer des rapports, visualiser des tendances et détecter des anomalies dans les données de log.
Pour ceux qui ne connaissent pas ce que c’est qu’un siem.Un index dans une base de données relationnelle est un outil qui permet d’accélérer la recherche d’informations. Il fonctionne un peu comme l’index d’un livre.
Pour bien comprendre, imagine que tu as un livre très épais et que tu cherches un mot spécifique. Sans index, tu devrais parcourir chaque page du livre jusqu’à trouver ce que tu cherches. Avec un index, tu peux simplement regarder dans l’index, trouver le mot que tu cherches, et voir directement à quelle page il se trouve.
Dans une base de données, un index fonctionne de la même manière. Plutôt que de parcourir toutes les lignes d’une table pour trouver une donnée spécifique, l’index permet de localiser rapidement ce que l’on recherche. Sur le plan technique, c’est une table supplémentaire associée à la table principale dans la base de données. Elle contient une ou plusieurs colonnes de la table principale, triées de manière spécifique.
Un bon index peut rendre une base de données beaucoup plus performante, en accélérant les opérations de lecture. Cependant, il faut noter que la création d’un index peut ralentir les opérations d’écriture (comme l’ajout ou la modification de données), car l’index doit être mis à jour chaque fois que les données changent
Pour conclure , les bases de données sont des systèmes de stockage organisés qui permettent de gérer et d’accéder à des données de manière efficace. Elles sont utilisées pour stocker divers types d’informations, telles que les utilisateurs, les produits, les transactions, etc. Les éléments clés à retenir sur les bases de données sont les suivants :
- Structure : Les bases de données peuvent être relationnelles, orientées document, orientées colonnes, clé-valeur, ou graphe, selon leur modèle de données et la manière dont elles organisent les informations.
- Tables : Les données sont organisées en tables, qui sont composées de lignes et de colonnes. Chaque ligne représente un enregistrement unique et chaque colonne représente un attribut de cet enregistrement.
- Clés primaires : Chaque table possède une clé primaire, qui est un attribut unique permettant d’identifier de manière univoque chaque enregistrement dans la table.
- Clés étrangères : Les tables peuvent être liées entre elles à l’aide de clés étrangères, qui établissent des relations entre les enregistrements de différentes tables.
- Requêtes : Les données peuvent être extraites, mises à jour, supprimées ou insérées dans une base de données à l’aide de requêtes SQL (Structured Query Language) ou d’autres langages de requête spécifiques au système de gestion de base de données utilisé.